A few weeks ago, while scrolling twitter and sharing some tweets I randomly thought about long random numbers at the end of every tweet URL. Unlike YouTube’s base-62 encoded URLs these were just digits, no letters, no mixed case. At first glance, it didn’t look like a simple incremental counter and the numbers seemed structured yet unpredictable. I got curious and that got me thinking how does Twitter generate unique IDs at such a massive scale?

Breaking Down Twitter Snowflake ID
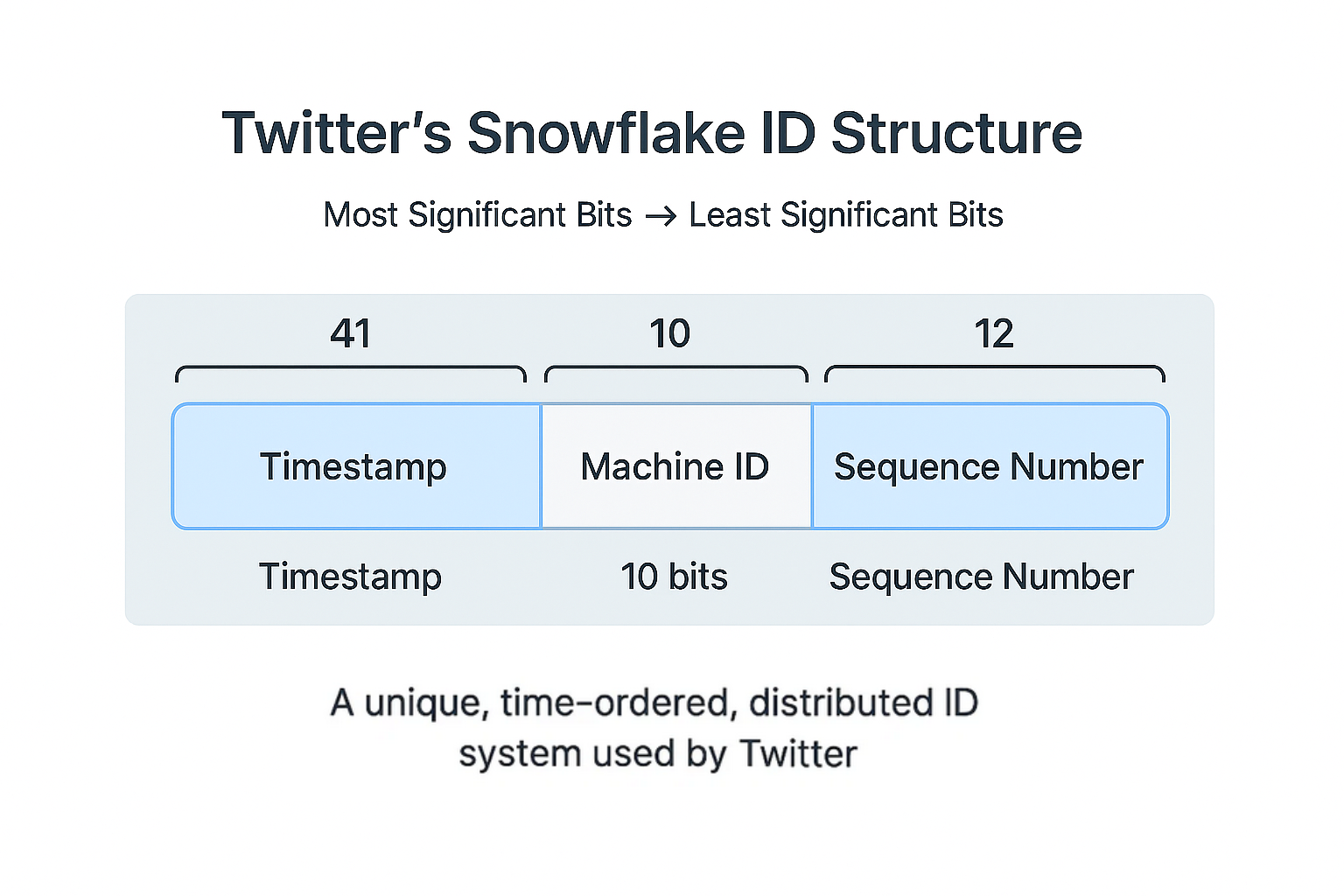
Twitter doesn’t use a simple incremental counter for tweet IDs. Instead, it uses a unique time-based ID generation system called Snowflake. Every tweet on Twitter/X is assigned this “unique Snowflake ID”. This ID is a structured identifier that encodes:
- A Timestamp — when the tweet was created
- A Machine ID — which datacenter and server generated it
- A Sequence Number — to differentiate tweets created in the same millisecond
Let’s decode a real tweet ID and see how this works in action!
This is a tweet I posted on Pi Day (March 14, 2025, at 7:28 PM IST) https://x.com/Navadeep_naidu7/status/1900547158165840235 and as you can see there is a unique ID 1900547158165840235 generated for my tweet.
When you convert this into a 64-bit binary and decode it using bit operations:
1. The Timestamp (extracted by right-shifting 22 bits)
The timestamp portion gives us: 453125752965 milliseconds since Twitter’s epoch.
Twitter Epoch = November 4, 2010, 01:42:54.657 UTC
Adding the epoch: 453125752965 + 1288834974657 = 1741960727622 milliseconds
Converting to human-readable time:
- UTC Time: Friday, March 14, 2025, 1:58:47.622 PM
- IST Time: Friday, March 14, 2025, 7:28:47.622 PM
This matches very closely with when I posted the tweet (within the same second).
2. The Machine ID (bits 12–21)
Using bit masking: (ID >> 12) & 0x3FF
This gives us 422, which represents the machine or worker node that generated the tweet ID. Twitter uses this to ensure that multiple datacenters or nodes can generate IDs in parallel without any clashes.
3. The Sequence Number (last 12 bits)
Using bit masking: ID & 0xFFF
This gives us 363 in decimal. It’s a sequence number to differentiate tweets generated in the same exact millisecond.
That means, during that millisecond (13:58:47.622 UTC), this was the 364th ID generated by this server in that millisecond (sequence numbers start from 0, so 363 means 364 total).
Final Breakdown
Inside this single Snowflake ID:
- Timestamp → 1741960727622 ms → March 14, 2025, 7:28:47 PM IST
- Machine ID → 422 (Twitter internal node)
- Sequence → 363 (this was the 363rd tweet generated that millisecond on this machine)
Why Snowflake? The Problem Twitter Solved
Before diving deeper, let’s understand why Twitter needed Snowflake in the first place. Traditional approaches to ID generation face serious challenges at Twitter’s scale:
Sequential IDs: Simple auto incrementing integers work great for single databases, but when you’re serving 500+ million tweets per day across multiple datacenters, coordination becomes a nightmare. You’d need a central authority to assign IDs, creating a single point of failure.
UUIDs: While globally unique, UUIDs are 128-bit random strings that are expensive to store, index, and don’t provide any temporal ordering crucial for timeline feeds.
Database-generated IDs: Relying on database auto-increment across sharded systems leads to coordination overhead and potential conflicts.
Twitter needed something that was:
- Globally unique across all datacenters
- Sortable by time (newer tweets have higher IDs)
- High performance (no network calls or database coordination)
- Compact (64-bit integers are efficient)
The Brilliant Design Choices
Time-Ordered by Design
Since the timestamp is the most significant part of the ID, Snowflake IDs are naturally ordered by creation time. This means:
- Newer tweets always have higher IDs than older ones
- Database indexes perform optimally
- Timeline queries are incredibly efficient
Distributed Generation
With 10 bits for machine ID, Twitter can have up to 1,024 different worker nodes generating IDs simultaneously without any coordination. Each node generates IDs independently, eliminating bottlenecks.
High Throughput
The 12-bit sequence number allows each machine to generate up to 4,096 unique IDs per millisecond. Across 1,024 machines, that’s potentially 4.2 million IDs per millisecond or 4.2 billion IDs per second!
Real-World Impact
Let’s put this in perspective with some calculations:
Storage Efficiency: A 64-bit Snowflake ID takes 8 bytes, compared to a 36-character UUID string which takes 36 bytes. For Twitter’s billions of tweets this saves massive amounts of storage.
Index Performance: Database B-tree indexes work optimally with sequential data. Since Snowflake IDs are time-ordered, new tweets always append to the end of indexes rather than causing expensive reorganizations.
Timeline Queries: When you scroll through your Twitter feed, the system can efficiently fetch tweets by simply querying for IDs greater than your last seen ID.
The Scalability Math
Let’s crunch some numbers on Snowflake’s theoretical limits:
- Time: 41 bits = ~69 years from Twitter’s epoch (March 2010)
- Machines: 10 bits = 1,024 concurrent ID generators
- Sequence: 12 bits = 4,096 IDs per millisecond per machine
- Total capacity: 4.2+ billion IDs per second globally
Even at Twitter’s peak usage this system has tremendous headroom.
Implementation Considerations
If you’re thinking about implementing Snowflake for your own system, here are key considerations:
Clock Synchronization: All machines must have synchronized clocks (typically using NTP). Clock drift can cause ordering issues.
Machine ID Management: You need a reliable way to assign unique machine IDs and handle machine failures/restarts.
Sequence Reset: The sequence counter resets every millisecond. If you generate more than 4,096 IDs in a single millisecond on one machine, you need to wait for the next millisecond.
Epoch Choice: Choose your custom epoch wisely it determines how long your system can run. Twitter’s choice of 2010 gives them until ~2079.
Beyond Twitter: Snowflake’s Legacy
Twitter open-sourced Snowflake, and it’s now widely adopted across the industry. Companies like Discord, Instagram, and countless others use variations of this design. The core concept has become a fundamental pattern in distributed systems.
Some popular implementations include:
- Discord: Uses a modified Snowflake with different bit allocations
- Instagram: Adapted Snowflake for their photo IDs
- Mastodon: Uses Snowflake-style IDs for distributed social media
Code Example: Decoding Any Snowflake ID
Here’s how you can decode any Twitter Snowflake ID yourself:
def decode_snowflake(snowflake_id):
# Twitter's custom epoch, November 4, 2010, 01:42:54 UTC
TWITTER_EPOCH = 1288834974657
# Extract timestamp by right-shifting 22 bits (10 machine + 12 sequence)
timestamp_ms = (snowflake_id >> 22) + TWITTER_EPOCH
# Extract machine ID (bits 12-21, so mask and shift)
machine_id = (snowflake_id >> 12) & 0x3FF # 0x3FF = 1023 (10 bits)
# Extract sequence (last 12 bits)
sequence = snowflake_id & 0xFFF # 0xFFF = 4095 (12 bits)
# Convert timestamp to human readable
import datetime
dt = datetime.datetime.fromtimestamp(timestamp_ms / 1000, tz=datetime.timezone.utc)
return {
'timestamp_utc': dt.strftime('%Y-%m-%d %H:%M:%S.%f UTC')[:-3], # Remove last 3 digits for milliseconds
'machine_id': machine_id,
'sequence': sequence,
'raw_timestamp_ms': timestamp_ms
}
# Try it with the example tweet
result = decode_snowflake(1900547158165840235)
print(result)
# This should output something like:
# {'timestamp_utc': '2025-03-14 13:58:47.622000 ',
# 'machine_id': 422,
# 'sequence': 363,
# 'raw_timestamp_ms': 1741960727622
# }Conclusion
Twitter’s Snowflake is more than just an ID generation system, it’s a masterclass in distributed system design. By encoding time, machine identity, and sequence information into a single 64-bit integer Twitter created a solution that scales to billions of operations while maintaining ordering and uniqueness guarantees.
The next time you see those long numbers in a tweet URL, I hope you will remember and appreciate the engineering behind it! Thank you for reading, if you enjoy technical deep dives like this follow me on twitter sorry X @navadeep_naidu7